








如何做好可用性测试?高手总结了这6个阶段!

扫一扫 
扫一扫 
扫一扫 
扫一扫 本文带大家梳理一下可用性测试的概念和研究方法,帮助大家做好可用性测试。 拓展阅读: 设计师第一次做可用性测试,这篇文章就够了!背景:去年 12 月因公司一个改版项目,第一次全流程负责与参与设计调研工作。 阅读文章 >1. 什么是可用性? 可用性是衡量交互产品/系统质量的重要指标。指的是产品为特定用户用于特定目的时所具有的有效性、效率和主观满意度。 2. 什么是可用性测试? 通过观察有代表性的用户,完成产品中的各项任务,以洞察用户行为,界定出可用性问题。这是一种启发式的测试,顾名思义我们可以从中获得启发:用户可能怎么用我们的产品?有什么问题和不足?某个问题有多严重?都可通过这种小规模的测试给我们指明方向,一定会比自己空想要更加有效和客观。 3. 什么时候做可用性测试?
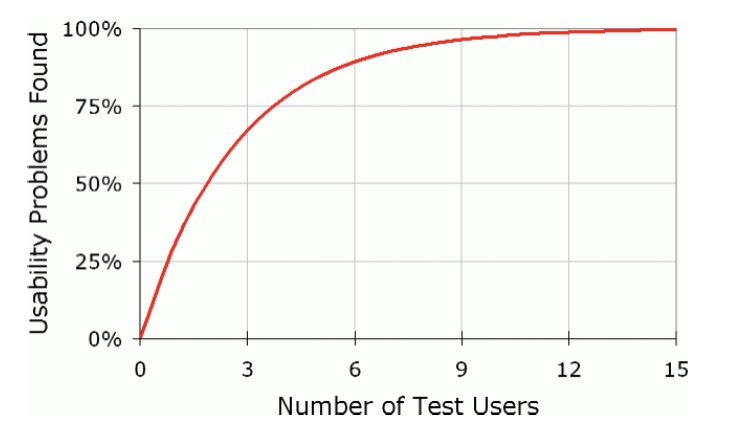
4. 测试需要多少名用户? 想做好可用性测试?5个人就够了!你也是半个心理学家我之前反复提过,我们体验设计现在的主流研究方法大部分从社会学或者心理学里移植而来,而可用性测试就直接脱胎于认知心理学的看家研究方法“实验法”。 阅读文章 >答:只需 5 名 根据尼尔森的数据模型,测试 5 个人可以发现 85%的问题。每次测试 5 名用户是效益最大化的做法,这也是行业建议的数量。
可能会有同学会问: “用户样本这么少,结果靠谱吗,能具有代表性吗?” 答:要知道无论是哪一种调研方式,都存在一定的优劣和局限性。 可用性测试最大的优点就是高效和相对客观。只要通过严谨的调研方法,我们就能够用最少的时间成本获得具有一定可信度的用户数据。因此对于调研方式的选择,是取决于当下所面临的情况。可用性测试在产品快节奏的迭代中不失为一种优秀的解决方案~ 执行方法1. 测试人员构成选出 2 名成员做测试员,一名负责提问和引导用户,另一名负责记录和补充提问。 2. 用户招募每次招募 5 名用户,对用户单独进行面对面测试。测试可通过线下或线上进行,但需要确保测试期间能够看到用户的使用界面。在招募用户前明确好测试目的,确保招募的用户为目标用户。 3. 测试提纲撰写测试提纲对应的是我们需要收集的测试数据,可分为以下三部分:测前问题、情景任务、测后访谈。 测前问题 用于了解用户的使用习惯、偏好等背景信息。 提问范例
情景任务 这部分的问题是整个测试中最核心的问题,在撰写时注意以下要点:
那如何写出一个优秀的情景任务呢?来看看下面的例子: 范例一
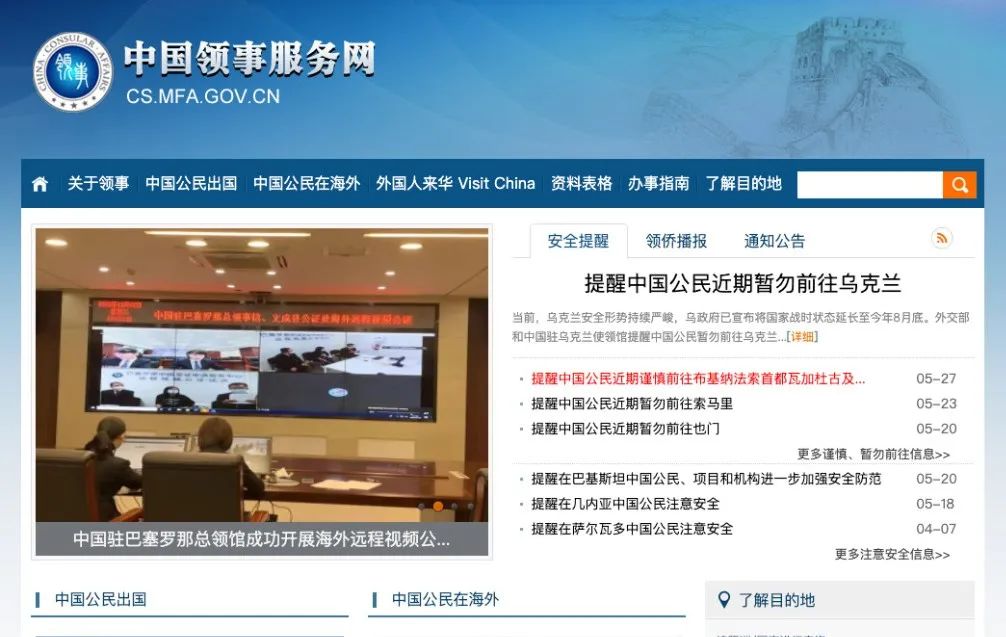
「原 版」 打开中国领事馆服务网,你能找到那个告诉你怎样申请护照的链接吗? 「优化后」 你的护照丢了,现在你需要办一个新的 — 去领事馆官网看看如何重办护照。 范例二
「原 版」 到京东买一个小猪佩琪玩具作为你女儿下周二的生日礼物。 「优化后」 下周二是你女儿的生日,你想送一个和她喜欢的卡通人物相关的礼物 — 看看京东网上有没有合适的。 测后访谈 对于测试中发现的问题、用户的使用感受与动机进行补充提问。 提问范例
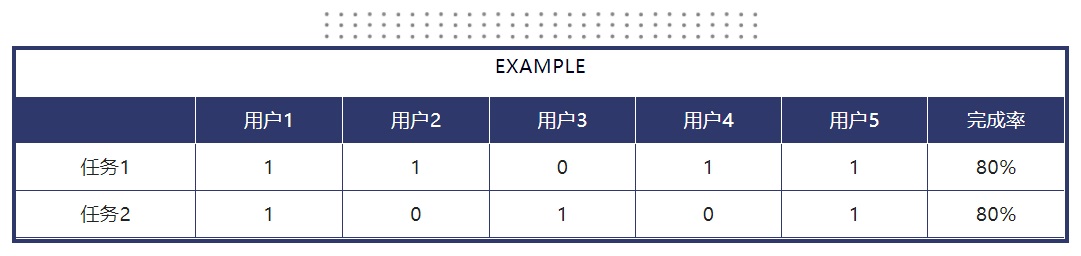
测试执行1. 测试准备 测试开始前,请提前设置好相机,以记录用户使用产品的过程,以便后期回看。 切记测试中的记录也是非常重要的,因为从头回看视频是很浪费时间的,可以在记录时标记视频录制的时间点,以提高数据整理的效率。 2. 破冰环节 在测试开始之前,向用户介绍测试目的,并与用户交流,鼓励他们说出内心想法。你可以用到以下话术: “这个测试是用来测我们产品的问题的,请你放心大胆提意见” “你思考的时候可以直接把你的想法说出来” “任务过程中我不会干涉你,但你如果遇到问题可以向我求助” 3. 测试期间 根据测试提纲进行提问,当发现用户在任务中出现问题时,可对用户进行引导或追问: “你是怎么理解这个页面上的信息的?” “你现在想做什么?” “现在发生了什么?” “你是怎么想的?” “期望接下来发生什么?” 但切记不要说太多话打断用户,这部分主要是观察而不是访谈 数据总结测试中可以参考关注以下纬度的数据,以便在后续的报告中做量化的总结。 1. 效率 完成时间 (* 感知时间有时候比实际时间更重要) 点击次数 2. 效能 完成率 求助次数 错误次数 3. 满意度 测试后访谈 皱眉、叹气等身体语言的次数 不由自主发出的消极/积极评论 将用户表现转化为定量数据1. 任务完成率可记录完成任务的用户数,从而得出任务完成率。 一般性任务的完成条件比较明晰,但也可以给部分任务定义成功标准,比如增加事件限制等。
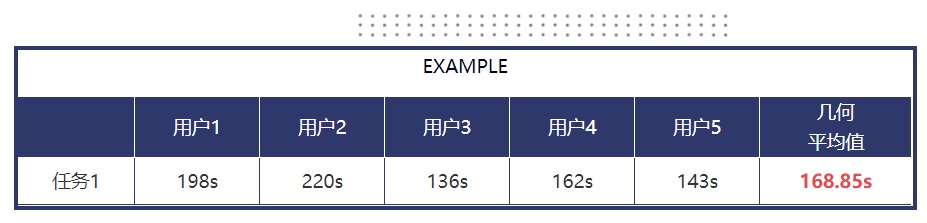
2. 任务完成时间任务时间即用户花费在一个任务上的时间,以往我们一般以均值的方式报告。可以配合任务完成率一起用~ 对于小样本量(样本量小于 25),计算均值使用几何平均值最佳,比中位数和平均值有更少的错误和偏差。
3. 其他评估指标评估有效性 任务完成率 错误数 需要帮助的次数 评估效率 任务完成时间 点击次数 评估满意度 皱眉,身体语言等 表达积极性/消极评价的频次 满意度量表(如:SUS 量表) 使用标准化量表使用标准化问卷测量用户的主观满意度,推荐使用 (SUS System Usability Scale)软件可用性量表,适用于小样本量的场景。量表内容如下:
1. SUS 分数计算方法分值转化: 奇数项(正面描述题),分值转化=原始分-1 偶数项(反面描述题),分值转化=5-原始分 SUS 量表总分=所有转化后的得分相加 X2.5(乘 2.5 之后变为百分值) 2. 注意事项:
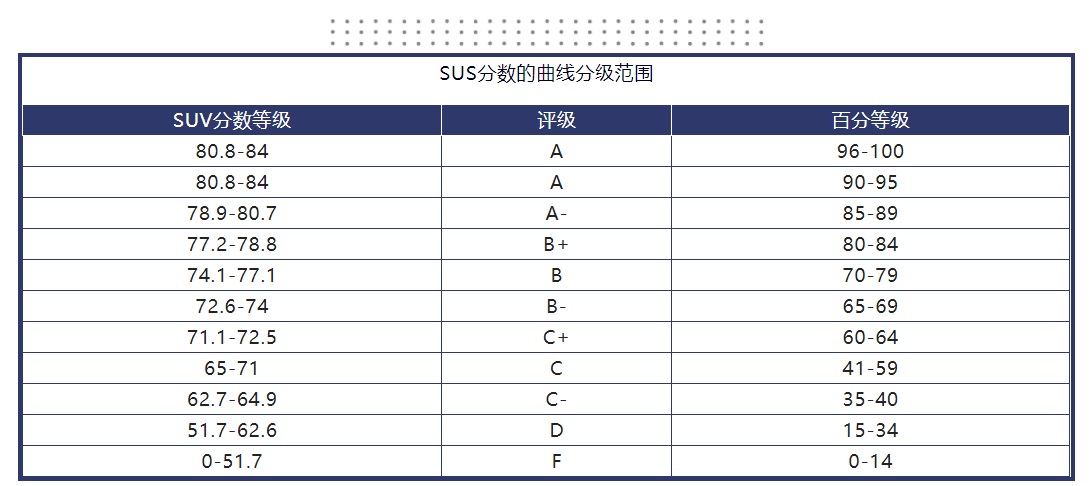
3. SUS 分数可以用来做什么?用于评级 对应下图,可得出字母等级评级、描述性评级和可接受范围与 SUS 分数之间的关系,可助于向非专业人士解释 SUS 分数的结果。
① 字母等级:A级: ≥90分 ; B级: ≥80分;C级: ≥70分;D级: ≥60分;F级: <60分 ② 描述性评级:完美(Best Imaginable): 100分; 优秀(Excellent): 85-99分; 良好(Good): 73-84分;合格(OK):52-72分; 差劲(Poor): 39-51分; 糟糕透了(Worst Imaginable):39分以下 ③ 可接受范围:可以接受(Acceptable): 70分以上; 中立(Marginal): 50-70分;不可以接受(Not Acceptable):50分以下 百分制等级 除此之外,也可以将 SUS 分数换算成百分等级来解释,百分等级的意思是指测量的产品或系统相对于总数据库里其他产品或系统的可用性程度。比如 SUS 得分是 73 分,其百分等级大约为 67,意味着比大约 66%的产品可用性更好。
*这个表格是 Jeff Sauro(2011)通过 446 个研究,超过 5000 个用户的 SUS 反馈的数据库。这个基准数据也可以由内部团队制定。 制定优先级标准量化过程可分为三步:
1. 问题严重性评定: 列出测试中出现的问题,并分别打分——4分制,评定标准见下表(例:用户在某页找不到某功能的入口,这个问题导致了一个严重的挫折,严重性分值为3分)
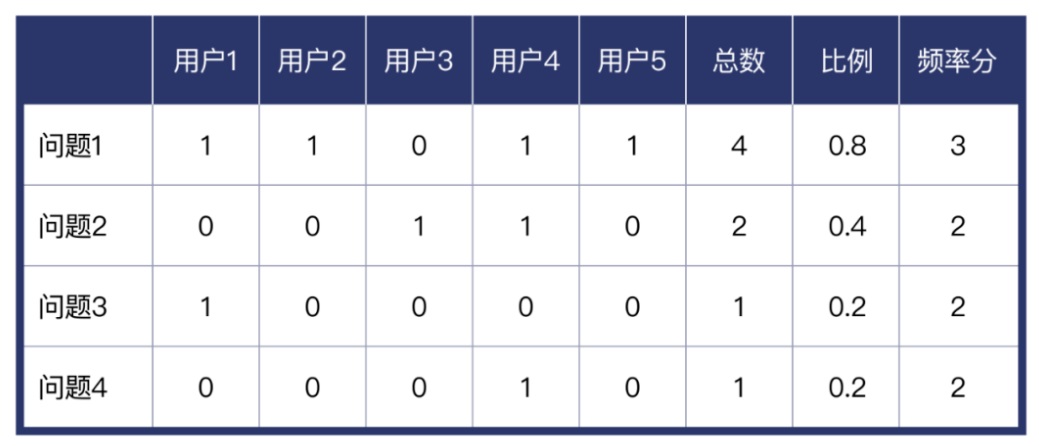
*当多个用户表现得不一致时,若程度分最高的比例大于等于 25%则按最高分计算,小于 25%则按低级的分数计算。(例:某问题在 2/5 用户上体现为 4 分,在 2/5 用户上体现为 2 分,那就按 4 分算;如果在 1/5 用户上体现为 4 分,在 2/5 用户上体现为 2 分,那就按 2 分算) 2. 问题发生频率评定: 评估每个问题在总样本中发生了几次——4分制,评定标准见下表
统计表格格式参考:
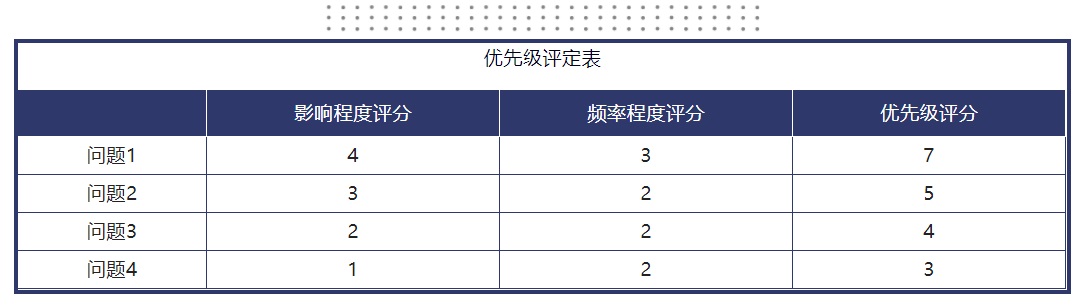
3. 优先级评分计算: 优先级分数=严重程度分+频率程度分 故最高 8 分,最低 2 分
当然,文中介绍的是一种处理思路,大家可适当调整测试标准,使其更适用于实际情况。如进行加权处理,或是增加新的评定指标~ 通过这些方法,可以将我们观察到的用户表现,转成量化的数据,使测试结果更加直观、具有说服力。快来试试吧 欢迎关注作者微信公众号:「ASAK设计」
手机扫一扫,阅读下载更方便˃ʍ˂ |






@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







